In this guide, you’ll learn how to OCR and extract data from specific coordinates in an image or PDF document using Power Automate and Muhimbi PDF Connector.
Using Power Automate to Convert to PDF
This example takes you through extracting text from an image-embedded PDF file and updating the extracted text to the MS SharePoint library in a custom column created for this purpose.
From a high-level perspective, the flow will look like what’s shown in the following image.
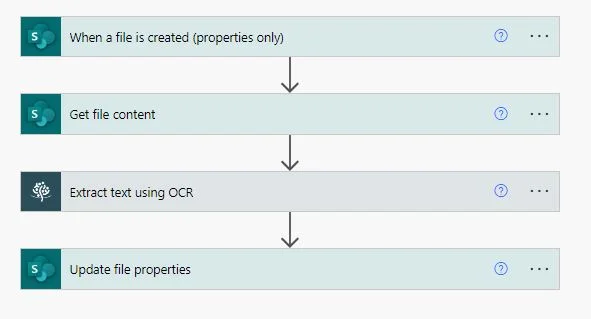
1: Creating a New Flow
Create a new flow and use the When a file is created (properties only) SharePoint Online trigger. Fill out the URL for the site collection and select the relevant site address, library name, and folder from the dropdown menu.
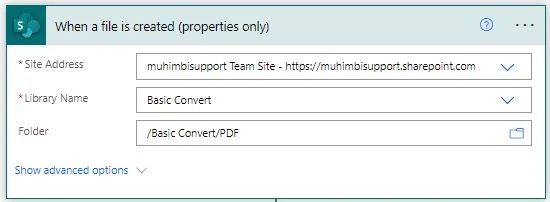
2: Getting the File Content
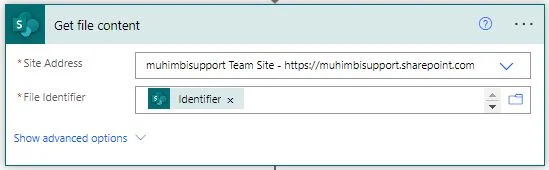
Insert MS SharePoint’s Get file content action and fill it out as shown in the screenshot below. Substitute the Site Address field with a suitable value, and fill in the File Identifier field with the output value of the When a file is created (properties only) action.
3: Extracting Text Using OCR
Insert Muhimbi’s Extract text using OCR action, and fill it out as shown in the screenshot below.

- Source file name — Name of the source file, including its extension.
- Source file content — Content of the file to OCR. Select Body, which is the output value of the Get file content action.
- Language — Select the language of the OCR file. In this case, select English.
- X Coordinate — Select the X coordinate (in pts, 1/72 of an inch) to be OCR’ed. In this case, enter 150.
- Y Coordinate — Select the Y coordinate (in pts, 1/72 of an inch) to be OCR’ed. In this case, enter 368.
- Width — Select the width (in pts, 1/72 of an inch) to be OCR’ed. In this case, enter 92.
- Height — Select the height (in pts, 1/72 of an inch) to be OCR’ed. In this case, enter 80.
- Page number — Select the page number(s) to be OCR’ed. Leave this blank to OCR all pages or when OCR’ing images.
4: Updating File Properties
Insert an MS SharePoint Update file properties action, and fill it out as shown in screenshot below. This will update the OCR’ed text back to the column in the library for the item specified by the item ID.
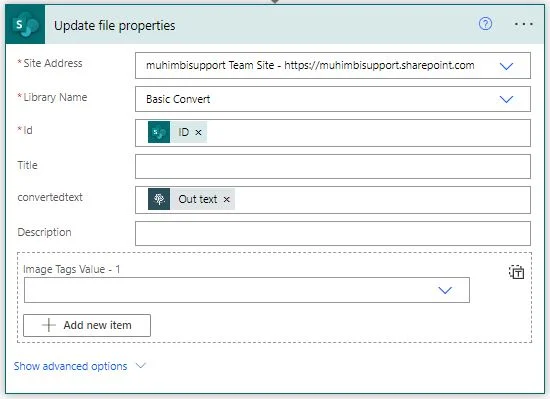
- Site Address — Select the site address of the MS SharePoint library to which the OCR’ed content needs to be updated.
- Library Name — Select the MS SharePoint library to which the OCR’ed content needs to be updated.
- Id — This is the unique identifier of the item to be updated. In this case, select ID, which is the output of the When a file is created (properties only) action.
- Item — This is the column name of the library to which data has to be updated. In this case, convertedtext is the name of the column. Enter Out text in this field, which is the output of the Extract text using OCR action. You can update the value based on whatever the column is named in your scenario.
5: Publishing the Workflow
Publish the workflow and upload an image-embedded PDF file in the specified document library. After a few seconds, the flow will trigger, and the OCR’ed content will be updated in the convertedtext column in your MS SharePoint library.
