


Our no-code OCR server, Autobahn DX, allows users to set up and customize workflows with ease and run them automatically. It also works well when processing large volumes of documents, thanks to an AI-powered OCR engine.
This post details how to create automated PDF OCR workflows with Autobahn DX.
Step 1: Setting Up a New Job
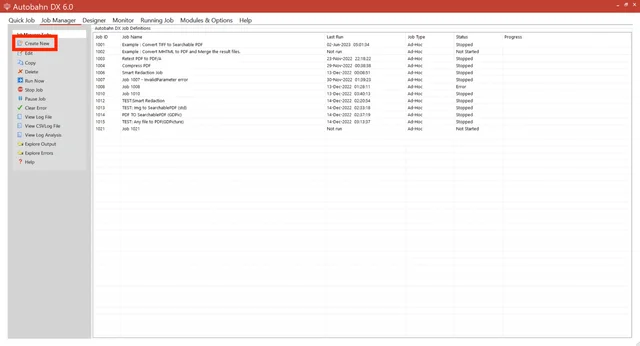
Click Create New. Fill in the Source Folder and Destination Folder fields by clicking the magnifying glass to the right of these fields. The source (input) folder is where all the files you want to process should go. The destination (output) folder is where all the processed files will end up.
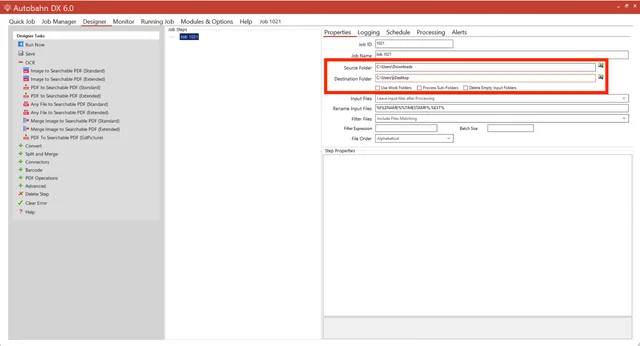
Step 2: Selecting OCR to Process Your Files
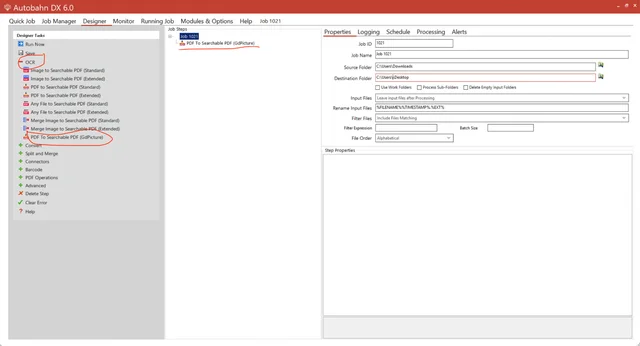
Under OCR, select PDF To Searchable PDF (GdPicture). This step uses the GdPicture engine, which is faster than the other OCR options, as it processes pages simultaneously with multithreading.
Step 3: Choosing the Number of Threads
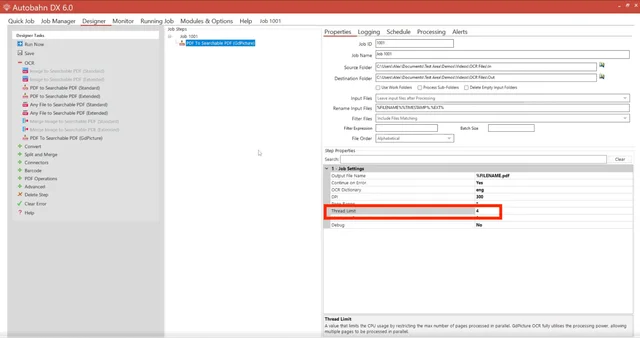
As OCR is a CPU-intensive process, you can choose the amount of threads to use by specifying the number in the Thread Limit field.
Step 4: Saving the Job
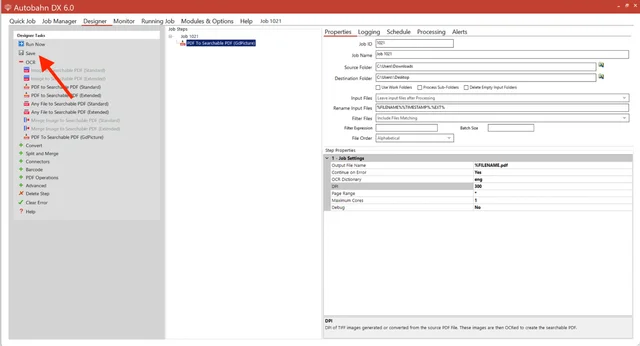
Save the job and return to the Job Manager.
Step 5: Scheduling the Job
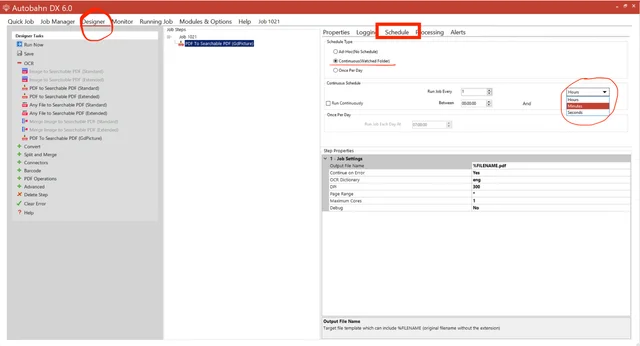
To schedule the job to run automatically, select Designer, and then click the Schedule tab. You can choose the Once Per Day option and run jobs out of hours. Or, you can choose the Continuous (Watched Folder) option and set the job to run every minute. If you work with multiple jobs, you should stagger the times that they run.
Step 6: Moving Files to the Archive
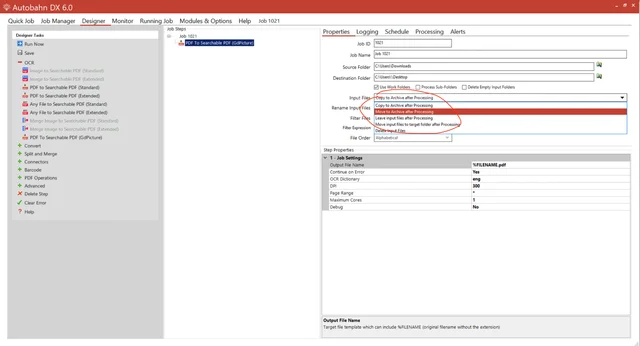
After processing, you’ll be prompted to enable the work folder, which is an intermediary folder between the source folder and the destination folder. If you leave the files in the same input folder with a continuous job, they’ll be continually reprocessed. Change the default settings in the Input Files field to Move to Archive after Processing.
Step 7: Setting a Document Count Limit
Finally, set a document count limit. The example above sets a batch size of seven. That means that for each run, every minute, seven files will be chosen out of the total number of files that are in the input folder, and they will be run through first.
This is useful for very large volumes where you have thousands of documents and you want some output files to be available earlier without waiting for every file to be processed.
Step 8: Saving the Job Settings
Click Save and go to the Job Manager tab. Because it’s continuous, it will have already started running through the files. Once the job is run, the status will change. If it tries to run when there are no files in the output folder, it will immediately go back on, stand by, and try and run the next minute to see if any files have been added to the target folder.
After the job is finished, go to the output folder and check the processed files. Now all these PDF files are OCRed and fully searchable.
Conclusion
If you want to try these steps yourself, download the free trial of Autobahn and make your documents searchable. Or, if you prefer to see these steps in action, check out our video tutorial below.